The Tool
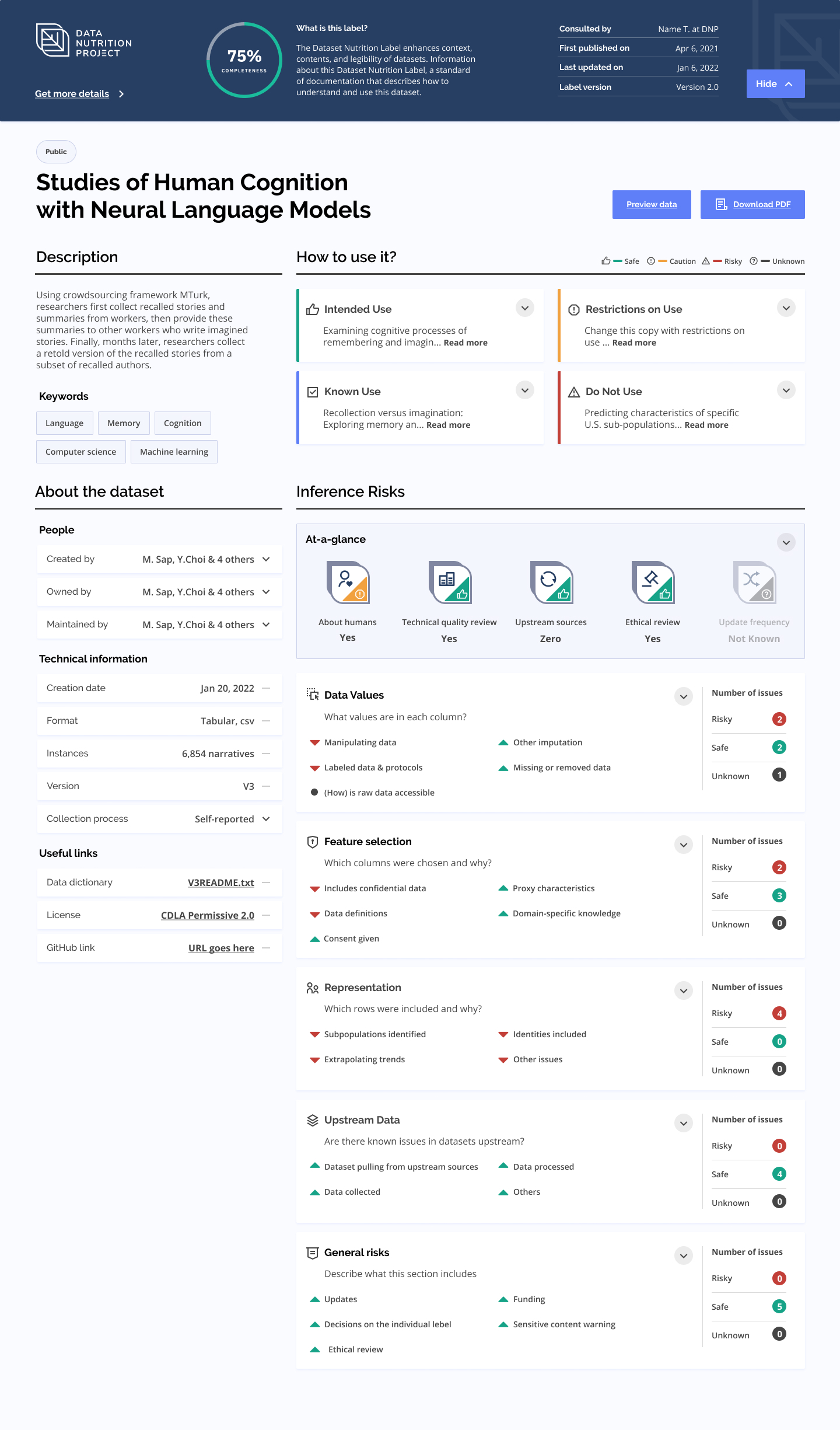
A "nutrition label" for datasets.The Data Nutrition Project aims to create a standard label for interrogating datasets.
Our belief is that deeper transparency into dataset health can lead to better data decisions, which in turn lead to better AI.
Founded in 2018 through the Assembly Fellowship, The Data Nutrition Project takes inspiration from nutritional labels on food, aiming to build labels that highlight the key ingredients in a dataset such as meta-data and populations, as well as unique or anomalous features regarding distributions, missing data, and comparisons to other ‘ground truth’ datasets.
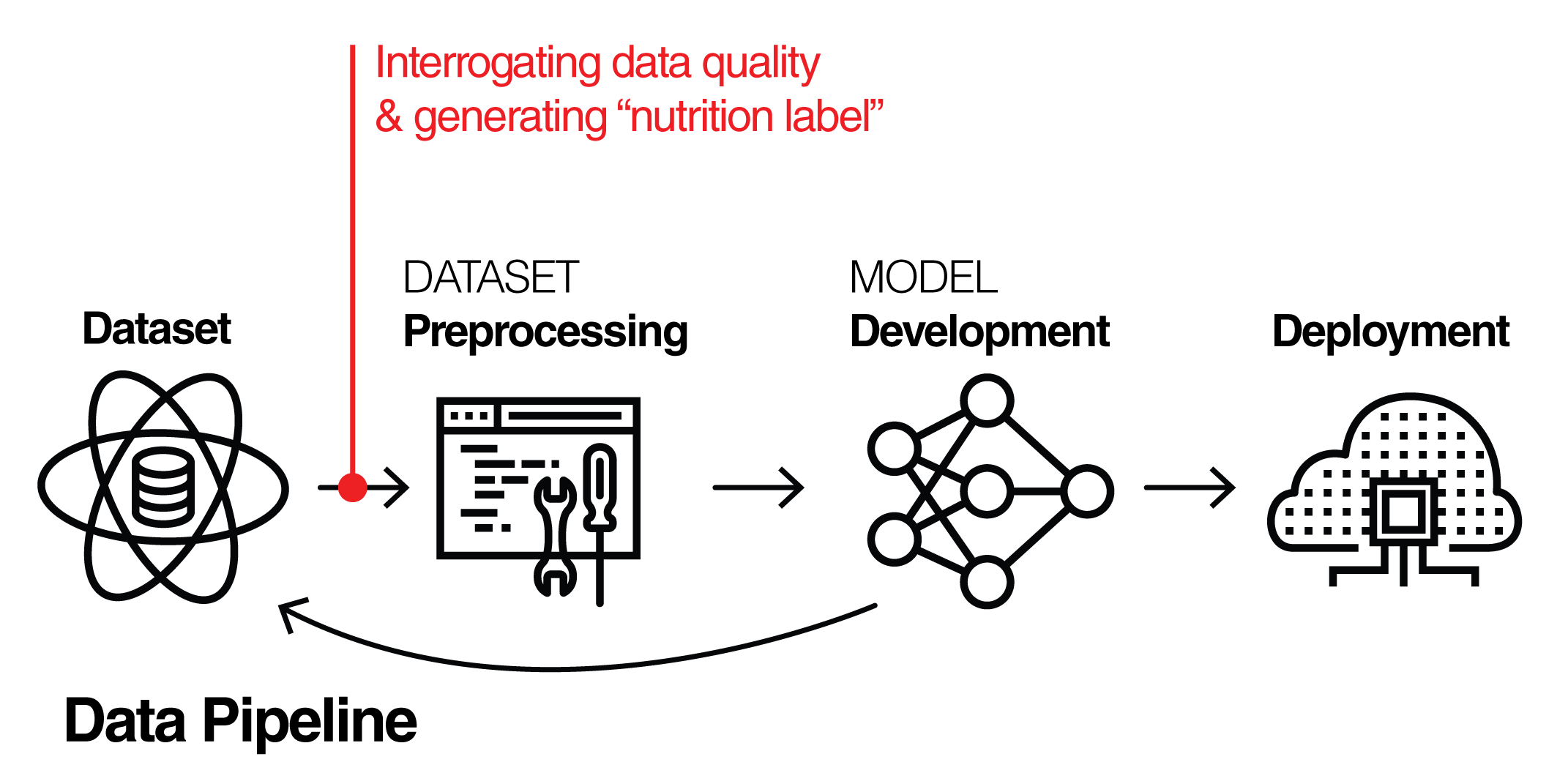
Building off of the ‘modular’ framework initially presented in our 2018 prototype and based on feedback from data scientists and dataset owners, we have further adjusted the Label to support a common user journey: a data scientist looking for a dataset with a particular purpose in mind. The second generation Dataset Nutrition Label now provides targeted information about a dataset based on its intended use case, including alerts and flags that are pertinent to that particular use. Read more about the methodology behind the second generation in our most recent white paper.